
UEEN1043:you are asked to demonstrate a program that uses the container class in Python :Object-Oriented Concept and Programming Techniques Assignment, UTAR, Malaysia
Assignment Type
Individual Assignment
Subject
UEEN1043: Object-Oriented Concept and Programming Techniques
Uploaded by Malaysia Assignment Help
Date
03/26/2022
In this assignment, you are asked to demonstrate a program that uses the container class in Python, i.e. list and dict, to automatically find all the duplicated book items in the UTAR library collection. You can only use the Python built-in functions to perform the task. Use of any advanced modules other than CSV, such as pandas and NumPy, will immediately lead to a zero
mark.
Your task in this assignment is to find out the total number of duplicated titles in the input file called library-titles.csv. Each row of the input file contains the related information of one single book item.
Stuck in This Assignment? Deadlines Are Near?
- Database keeping the book; DB
- Title of the book;
- Each of the books is given at least one of the two standard numbers; International Standard Serial Number (ISSN) or International Standard Book Number (ISBN):
◦ An ISSN or e-ISSN (the ISSN of the digital edition of the book) of the book, must be 8 digits, either with separators of ‘-’ or without any separator;
◦ An ISBN or e-ISBN (the ISBN of the digital edition of the book) of the book, must be either 10 digits or 13 digits, either with separators of ‘-’ or without any separator;
The input file contains all kinds of errors that require us to clean or tidy up and below are the few things you must do:
• It is possible that a book is given all four standard numbers, but some of them may not conform to the aforementioned digit formats. In these cases, you should ignore them by resetting these mistaken numbers to a null string, instead of dropping, them before comparison.
• Next, remove all the characters after the first slash symbol, ‘/’, together with the first slash symbol itself in all the standard numbers, before comparison.
• Next, a character ‘X’ of ‘x’ within the ISSN, e-ISSN, ISBN, or e-ISBN numbers is considered as a wildcard character that can match any (one) number during comparison.
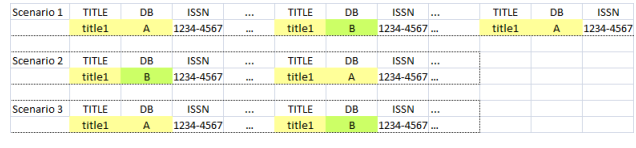
If any pair of book items from two different DBs satisfy one of the conditions below, they are classified into the same duplication group:
1) if their titles are the same and all their ISSN, e-ISSN, ISBN, and e-ISBN are nulled; or
2) if the standard numbers of a book item are equal to or form a subset of the
corresponding standard numbers of the other book item; otherwise, they are considered
different; or
3) if a book item that has empty fields in all its standard numbers matches the other book item in the title.
In the end, you output all the duplication groups to a single CSV file called duplication.csv in which each row represents one distinct duplication group and contains the information, i.e. TITLE, DB, ISSN, e-ISSN, ISBN, and e-ISBN numbers, of all entries classified into the group. However, you need to remove duplication from the same DB and keep only one record. Lastly, you need to sort the listing within each row alphabetically by the names of DBs. The example below illustrates a few scenarios, but only scenario 3 is considered the correct one. The format of the CSV file is described in the sample output duplication_example.csv.
Next, based on the duplication you found, you need to create a network graph, with its structure similar to the figure below, as an output in png format, called relation.png.
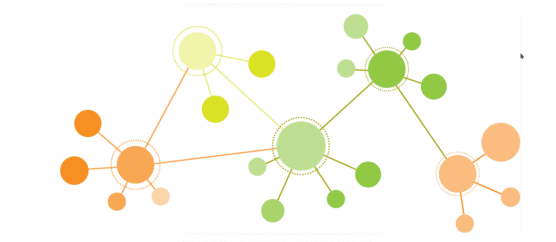
In the figure, you need to
- use a node to represent a DB ;
- use an edge to indicate a relationship between two nodes, i.e. if there are the same titles in the two DBs;
- if a DB does not have any relationship with any other DBs, it should be depicted as an orphan node, i.e. no edges connecting to it;
- if there are a lot of duplicated titles between two nodes, the colour of the edge line should be relatively darker concerning other edges with fewer duplicated titles;
- the size of a node that has more total number of titles should look relatively bigger than the size of a node that has a less total number of titles, i.e. you need to find a way to define the relative colour intensity and size.
You are free to find suitable modules using Google but the rule of plagiarism applies if all the codes or the output graphs are very similar. There are many ways to present the graph. To award, those who put in a lot of effort in searching for an appropriate module and presentation methodology, a poorly presented graph will not be awarded a full mark.
Get 30% Discount on This Assignment Answer Today!
Get Help By Expert
Our programming assignment helpers at Malaysia Assignment Help offer valuable assistance on UEEN1043: Object-Oriented Concept and Programming Techniques. our experts know how to make perfect assignment solutions. our experts also offer CSC116 Introduction To Computers And Programming Assignment Sample, CSC402 Programming I Assignment Sample, DSC551 Programming For Data Science UITM Assignment, CSC238 Object Oriented Programming Assignment Sample, etc more topics related to programming homework.

Recommended Assignments for You

Related University Assignments
- Software Engineering Assignment: Development of an AI-Powered Requirement Elicitation Agent for SMEs
- Basic Electronics Assignment: Characterization and Signal Amplification of an NPN Transistor Using Biasing Techniques and the Common-Emitter Configuration
- UGEA1243,UGEB1013 Circuit Theory Assignment 1: DC Source Design, Parameter Selection & Simulation Verification
- UKAF1083: The MASB had on 17 November 2011 announced and confirmed that Malaysia will converge with IFRS by 1 January 2012: Financial Accounting II Assignment, UTAR, Malaysia
- In KMK1143, this course covers many subareas of AI. However, AI is a much broader concept. The purpose of the final: Mental Health Chatbot Assignment, UTAR, Malaysia
- Some weeks ago, you (Danny Lim) a Certified Financial Planner (CFP) and a licensed Financial Planner met your old friend: Certified Financial Planner Assignment, UTAR, Malaysia
- BBMF 3073: Risk Management analysis is the discipline of identifying business risk and determining solutions to business risk: Risk Management Assignment, UTAR, Malaysia
- You are the project manager for your company’s MCP project. You are collaborating with your project team: Project Management Assignment, UTAR, Malaysia
- Kenchana Sdn Bhd is a trading company. It commenced its business on 1 October 2019 and closes its account: Taxation Assignment, UTAR, Malaysia
- GACT5113: Due to rising labour costs in Malaysia, Domain Computer, based in Singapore, is considering shifting part of its production facilities: Managerial Accounting Assignment, UTAR, Malaysia

Convincing Features

